
Paylaş

İnternetin ve teknolojinin gelişmesiyle birlikte bilginin gücünün öne çıkması, artan veri miktarı ve sosyal medya devrimi sayesinde iş yapma şeklimiz tamamen değişti.
Peki, bu kadar değerli olan bu veriler nerede barınıyor? Bugün baktığımızda Twitter her gün 7 TB, Facebook 10 TB ve bazı kurumlar her gün her saat TB’larca veri saklıyor.
Büyük veri; toplumsal medya paylaşımları, ağ günlükleri, bloglar, fotoğraflar, videolar, log dosyaları vb. gibi değişik kaynaklardan toparlanan tüm verinin, anlamlı ve işlenebilir biçime dönüştürülmüş şekline verdiğimiz bir isim.

Veriler doğru analiz metodları ile yorumlandığında, şirketlerin stratejik kararlarını doğru bir biçimde almalarına, risklerini daha iyi yönetmelerine ve innovasyon yapmalarına imkan sağlıyor.
 Geçmişe gittiğimizde ise 2006 yılında var olan veri büyüklüğü 0.18 zettabyte olarak hesaplanmışken, 2011 yılında bu sayı 10 kat katlanarak 1.8 zettabytes olarak hesaplanmıştır.
Geçmişe gittiğimizde ise 2006 yılında var olan veri büyüklüğü 0.18 zettabyte olarak hesaplanmışken, 2011 yılında bu sayı 10 kat katlanarak 1.8 zettabytes olarak hesaplanmıştır.
(Byte – kilobyte – megabyte – gigabyte – terabyte – petabyte – exabyte – zettabyte –yottabyte)
Veri saklama ve analiz etme…
Günümüz veritabanları bu çapta büyüyen verileri tutmakta yeterli değildir. Hard disklerin veri saklama kapasiteleri yıllar geçtikçe artarken, veriye erişim hızları bu hızlı artışa yetişememiştir.
Evet disk kapasiteleri terabytelar seviyesine ulaştı ve transfer hızı 100 MB/s oldu; fakat diskin içerisindeki tüm veriye erişmek yaklaşık 2 saat 30 dakika sürüyordu ve bu uzun süreyi azaltmak için yapılabilecek en iyi yol bir seferde birden fazla diske erişim yapmaktı.
Fakat bu defa da veriler paralel disklerde tutulduğunda 2 önemli sorunla karşılaşıldı:
1) Birinci problem: Donanım arızaları sonucu veri kaybı
Yani veri birden fazla diskte bulunduğu için, bir diskin başına gelebilecek herhangi bir donanımsal sıkıntıda içerisindeki veriler kaybolacaktır. Bunu önlemenin yolu, içerdiği verilerin birer kopyasının tutulmasıdır.
2) İkinci problem: Veri bütünlüğünün bozulması
Farklı disklerdeki veriler üzerinde yapılan işlemler sonucunda veri bütünlüğünün sağlanamaması.
Tabi ki de bunlara son vermek için geliştirilen sistemler var, ben bugün sizlere bunlardan biri olan Apache Hadoop’u anlatacağım.
Apache Hadoop?
Hadoop’un mantığı kümelenmiş (cluster) bilgisayarlar arasında, büyük hacimli verilerin dağıtık olarak işlenmesini sağlayan bir yazılım kütüphanesidir.

Hadoop aşağıdaki 3 temel özelliği ile bu parametrelerin hepsinin aynı anda gerçekleşmesini sağlayabilir:
Ölçeklenebilir
İhtiyaç duyulduğunda, verinin kendisini, formatını, yerini değiştirmeden, çalışan işlerin ve uygulamaların nasıl yazıldığını dikkate almadan yeni düğüm noktası eklenebilir.
Hesaplı çözüm
Yüksek hacimli verinin, fazla CPU gücü ile işlenmesini gerektiren paralel çözüm ihtiyaçlarını, daha ucuz veya hesaplı bilgisayar altyapısı ile gerçekleştirilmesini sağlar.
Hatadan kurtarma
Düğüm noktalarından biri ulaşılamaz olduğunda, sistem, gelen yükü diğer düğüm noktalarına paylaştırarak kesintisiz hizmete devam eder.
Disk üzerine kaydettiğimiz veriler, donanımsal veya yazılımsal bir problem meydana geldiğinde silinebilir dedik ama Hadoop ile proje geliştirdiğimizde HDFS üzerindeki verilerin kopyası faklı node’lara da kaydedildiği için hata durumunda veri kaybı yaşanmaz 😉
Peki nedir bu HDFS?
- Büyük miktardaki veriye yüksek iş/zaman oranı (throughput) ile erişim sağlayan Dağıtık Dosya Yönetim Sistemidir.
- Birçok makinedeki dosya sistemlerini birbiriyle bağlayarak tek bir dosya sistemi gibi gözükmesini sağlar.Bu dosya sistemi sayesinde sıradan sunucuların sabit diskleri bir araya getirilerek tek başına büyük bir sanal disk oluşturuluyor. Bu sayede çok büyük boyuttaki birden fazla dosyalar bu sistemde saklanabiliyor.
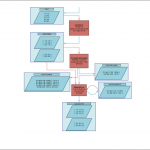
HDFS, DataNode ve NameNode dediğimiz 2 processden meydana geliyor:
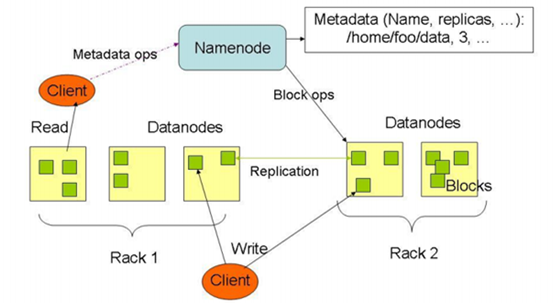 NameNode (Master) ana süreç olarak blokların sunucular üzerindeki dağılımından, yaratılmasından, silinmesinden, bir blokta sorun meydana geldiğinde yeniden oluşturulmasından ve her türlü dosya erişiminden sorumludur.
NameNode (Master) ana süreç olarak blokların sunucular üzerindeki dağılımından, yaratılmasından, silinmesinden, bir blokta sorun meydana geldiğinde yeniden oluşturulmasından ve her türlü dosya erişiminden sorumludur.
DataNode(Slave) ise işlevi blokları saklamak olan işçi (slave) süreçtir. Her DataNode kendi yerel diskindeki veriden sorumludur.
Aynı zaman da Hadoop Map Reduce ile gelen verileri parçalar.
Peki MapReduce nedir?
HDFS üzerindeki büyük dosyaları, verileri işleyebilmek için kullanılan bir yöntemdir.İstediğiniz verileri filtrelemek için kullanılan Map fonksiyonu ve bu verilerden sonuç elde etmenizi sağlayan Reduce fonksiyonlarından oluşan program yazıldıktan sonra Hadoop üzerinde çalıştırılır.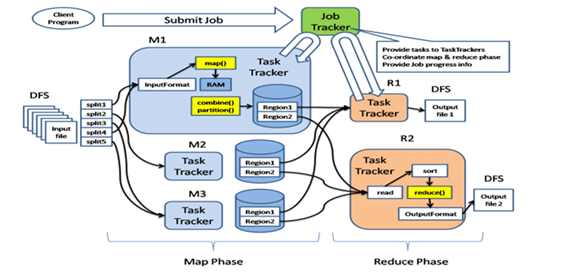
Kullanıcı Hadoop’ a bir MapReduce uygulaması gönderdiğinde:
JobClient gelen uygulamayı (job) JobTracker’a teslim etmek için hazır hale getirir.
JobTracker iş planlaması yapar (job scheduling) ve Map işlemini yapmak üzere işi TaskTracker’lara dağıtır.
Her bir TaskTracker bir MapTask yaratır ve verilen işlemi yapar. Bu sırada JobTracker işin ilerleme durumu hakkında TaskTracker’ lardan bilgi alır.
Map işlemlerinin sonuçları tamamlanmaya başladığında, JobTracker Reduce işlemini yapmak üzere işi TaskTracker’ lara dağıtır.
Her bir TaskTracker bir ReduceTask yaratır ve verilen işlemi yapar. Bu sırada JobTracker işin ilerleme durumu hakkında TaskTracker’lardan bilgi alır.
(Evet teorik kısmının biraz karışık olduğunu farkındayım,isterseniz daha basite indirgeyerek durumu bir örnekle açıklayalım).
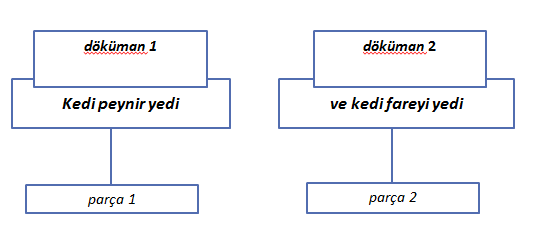
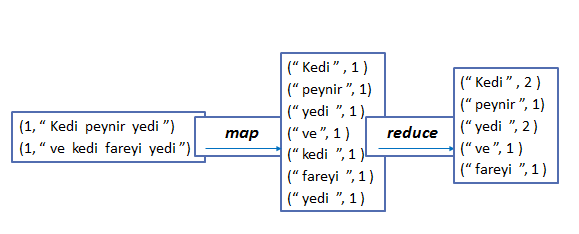
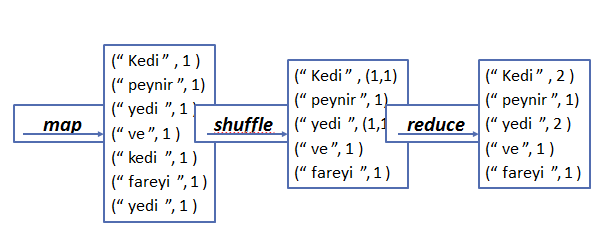
Sanırım bu örnek biraz daha açıklayıcı olmuştur.
Hadoop kurulumu nasıl yapılır?
Hadoop’un çeşitli modlarda kurulumunu yapmak mümkündür.
- Standalone (Dağıtık Olmayan) Mode
- Pseudo-Distributed (Dağıtık Mimariye Uygun Tek Sunucu) Mode
- Fully-Distributed (Dağıtık Mimariye Uygun Çok Sunucu) Mode
Ben sizlere benimde projemde kullandığım Multi-Node yani Fully-Distributed yapının kurulumunu anlatacağım. Multinode da iki ayrı işletim sisteminde iki ayrı Hadoop‘u ayağa kaldırıyor olacağız.
Clustered sistemlerde makineler temelde iki gruba ayrılıyorlar. İşlemleri yöneten ve o işlemleri gerçekleştiren denilebilir. Yani Master & Slave olarak adlandırılıyor. Master işlemleri ve dataları slavelere dağıtan makine oluyor, slaveler(işçi) ise kendilerine biçilen görevleri yerine getiriliyorlar.
Şu da bilinen bir gerçek ki Hadoop kümesindeki düğüm sayısı arttıkça performansı da doğrusal olarak artmaktadır.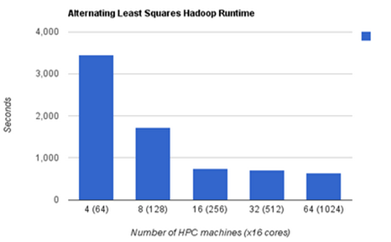
Hadoop Multinode Kurulum Aşamaları
- Tüm makinalara Java JDK kurulumu yapılır.
sudo apt-get install ssh sudo apt-get install rsync
- “su – hduserHadoop node ların yönetilmesi için SSH erişimine ihtiyaç duymaktadır.Hadoop sistemi içerisinde oluşturulan hduser kullanıcısı için SSH anahtar üretilmesi için ise
ssh-keygen -t rsa -P "" cat .ssh/id_rsa.pub >> .ssh/authorized_keys"
(Yukarıdaki komutlar şifresiz giriş için anahtar çifti üretmek ve anahtarla ssh erişimini aktif etmek için yapılır)
- Tüm bilgisayarlarda isteğe bağlı olarak özel bir kullanıcı grubu oluşturulur.
$ sudo addgroup hadoop $ sudo adduser –ingroup hadoop hduser
- Daha sonra kurulumu yapacağımız klasörü ve verilerin bulunacağı klasörü hazırlamamız gerekiyor. Eğer bu klasör yoksa yaratılıp, yetki vermeliyiz.Oluşturulan bu kullanıcı hesabı ile diğer tüm node.lara şifresiz ssh sağlanır.
- Apache sayfası üzerinden seçmiş olduğunuz Hadoop versiyonunu indiriyoruz.
- indirilen hadoop.tar.gz dosyası bu alana açılır.Açılan tar dosyasının içinde bulunan conf/hadoop-env.sh dosyası, JAVA_HOME değeri java kurulumunun olduğu dizini gösterecek şekilde değiştirilip kayıt edilir.
$ cd /usr/local $ sudo tar xzf hadoop-1.0.3.tar.gz $ sudo mv hadoop-1.0.3 hadoop $ sudo chown -R hduser:hadoop hadoop
- Kurulumun son aşamalarında ise bundan sonra conf klasörüne geçip konfigürasyon dosyalarını Multinode olarak çalışması için ayarlamamız gerekiyor.
export ]AVA_HOME=/usr/lib/jvm/j2sdk1.5-sun satirini silerek alttaki satirla degistirin. export JAVA-HOME=/usr/lib/jvm/jdk1.7.0
- HDFS ile ilgili ayarların yapıldığı hdfs-site.xml dosyasına varsayıln ayarı aşağıdaki şekilde olacak biçimde ayarlıyoruz.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
- $HADOOP-HOME/conf/masters dosyası içerisinde secondary namenode’un hangi makinalarda çalıştırılacağı bilgisi girilir.Kurulumun düzgün çalışıp çalışmadığını test etmek için
$ start-all.sh" hadoop'u baslatiyoruz
- Ve bir kereye mahsus olmak üzere Hadoop NameNode’un formatlanması gerekiyor.
$ hadoop namenode -format
- Formatlama işlemi bittikten sonra namenode’un tüm datanodelar ile birlikte başlatılması için
"start-dfs.sh" komutu calistirilir.
- Küme içindeki tüm birimlerin aynı anda kapatılması için Namenode terminalinde bin/stop-all.sh komutu çalıştırılır.
- Sistemin başarılı bir şekilde başladığını görmek için jps komutuyla süreçleri listeliyoruz.
hduser@ubuntu:/usr/local/hadoop$jps
TaskTracker,JopTracker,DataNode,SecondaryName Node, Jps,Name Node Bu süreçlerin hepsinin çalışıyor olması gerekiyor.
Apache Mahout nedir?
Mahout; Apache tarafından geliştirilmiş bir Open Source Machine Learning kütüphanesidir. Günümüzde birçok e-ticaret siteleri ve büyük datalarla ilgilenmek zorunda kalan sosyal medya ve reklam şirketleri bu teknolojiden yararlanma eğilimindedir.
Makine öğrenmesi, açıkça programlama olmadan öğrenmeyi ve önceki sonuçlara dayanarak gelecekteki sonuçların daha tutarlı olmasını sağlayan, yapay zekanın bir konusudur.

Apache Mahout üç temel konu içerir…
 2. Clustering
2. Clustering
 3. Classification
3. Classification
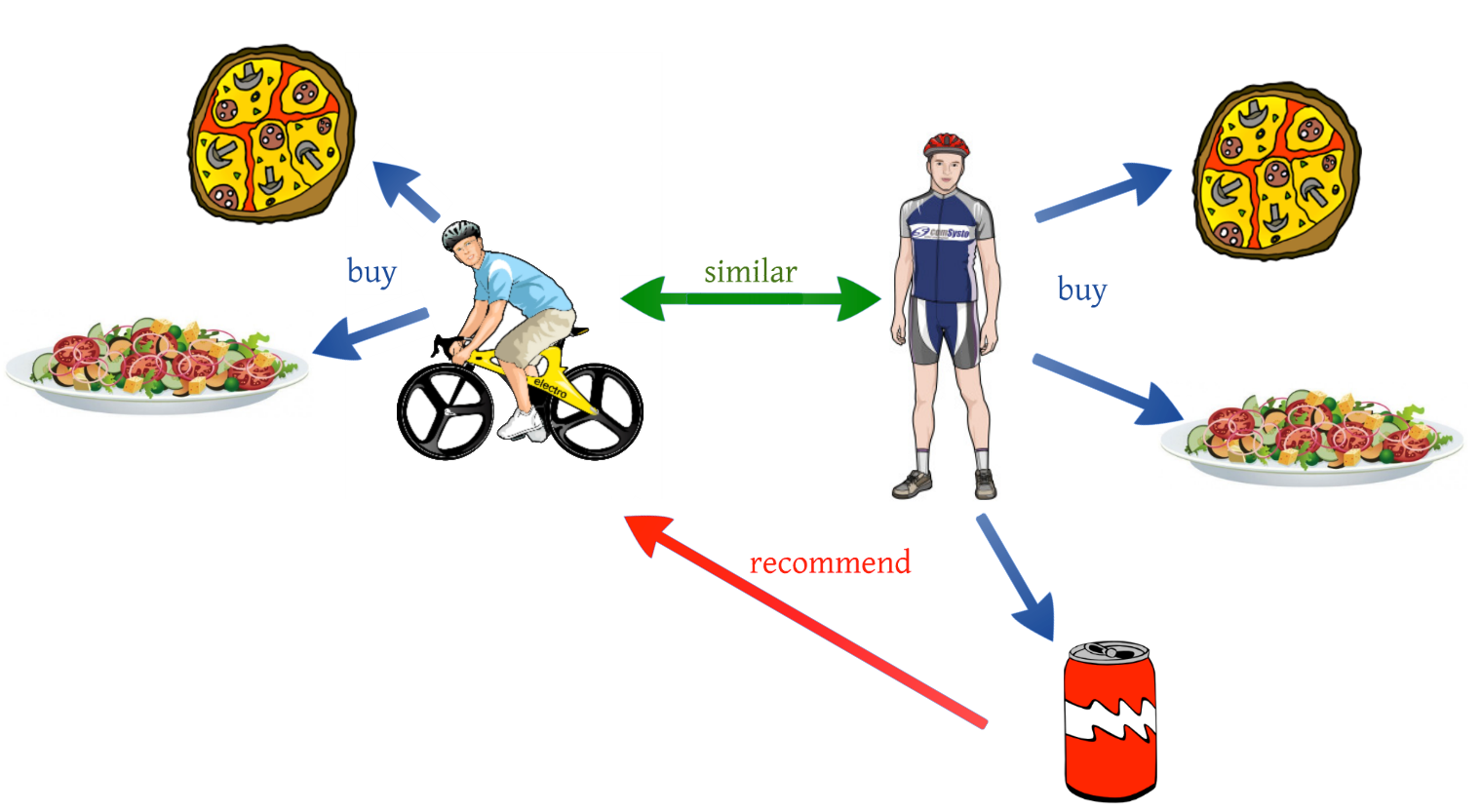
Ben sizlere bugünki konumda Recommender Engines’ten bahsedeceğim.
RecommenderEngine’ler günümüzde çoğunlukla Machine Learning tekniklerini kullanmaktadır.
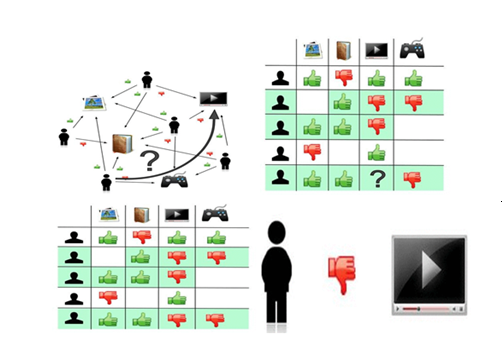
Apache Mahout Algoritmaları
- User-based Recommender
- Item-based Recommender
- Slope-One Recommender
User-based recommender
User-based recommender algoritması temelde benzer kullanıcıların tercihlerinden yola çıkarak öneride bulunur. u kullanıcısının, i filmine vereceği oyu tahmin etmek için; i filmine verilen oylar, oy verenlerin u’ya benzerlikleriyle ağırlıklandırılır.
Computing Root Means Squared Error
Ayrıca, Apache Mahout’ta Evaluate Factorization komutu kullanılarak RMSE hesabı yapılabilir.
u: user
i:item
r(u,i)=rate
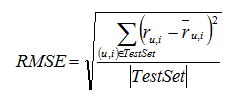
User–based Collobrative Filter :
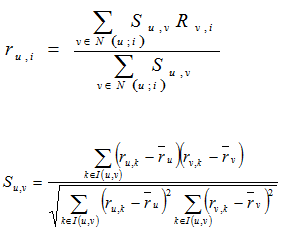
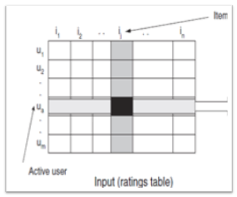
N(u;i) – i filmine oy veren kullanıcılar
I(u,v) – u ve v kullanıcıları tarafından oy verilmiş olan tüm filmler
Item-based Recommender
Item-based recommendation algoritması benzer itemlar üzerinden öneride bulunmaktadır. Itemların diğer itemlara nasıl benzerlik gösterdiğini ortaya çıkarır.
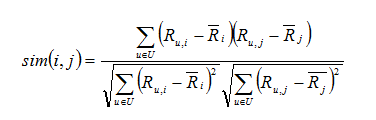
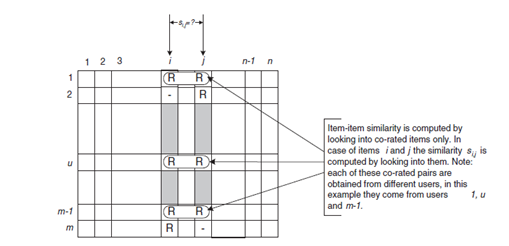
Hadoop üzerine Apache Mahout kurulum adımları
- Kurulumunu yapmak içinApache Maven dediğimiz , bir proje yönetim aracı olan ve projelerimizi belli bir standart içinde tutmak için projelerimizin iskeletini oluşturan yapıyı indiriyoruz.
sudo apt-get install maven - https://mahout.apache.org/ sitesine girerek indirmek istediğimiz Apache Mahout sürümünü indiriyoruz.
cd /home/pinar/Documents - Yeni bir klasör oluşturuyoruz.
mkdir mahout
- Oluşturduğumuz klasörün içine indirdiğimiz Apache Mahout’u entegre ediyoruz.
cd mahout- Ve son başarılı bir şekilde kurulumunu yaptığımız Mahout’u çalıştırıyoruz.
mvn install 
- Örnek verilerle çalışmak için Movilens ya da Netflix gibi sitelerden verileri indirip(u.data) üzerinde küçük projeler geliştirebilirsiniz.
 Şimdi sizlere projemde kullandığım, 100.000 rate olan 1000 kullanıcıdan oluşan ve 1700 filmi içinde barındıran (http://grouplens.org/datasets/movielens/ sitesinden verileri indirebilirsiniz) bir örnekle projemi anlatacağım, umarım sizler içinde yararlı olur.Öncelikle projemizde iki sanal makine kullanacağımız için VirtualBox’ları çoğaltıyoruz.(Master & Slave için).
Şimdi sizlere projemde kullandığım, 100.000 rate olan 1000 kullanıcıdan oluşan ve 1700 filmi içinde barındıran (http://grouplens.org/datasets/movielens/ sitesinden verileri indirebilirsiniz) bir örnekle projemi anlatacağım, umarım sizler içinde yararlı olur.Öncelikle projemizde iki sanal makine kullanacağımız için VirtualBox’ları çoğaltıyoruz.(Master & Slave için).
Projemizin amacı kullanıcıların filmlere vermiş olduğu puanlara bakarak, Collaborative Filtering yapısı ile diğer filmlere verebileceği puanları hesaplamak. Bunun için item similarity‘i kullanacağız. (Yukarıda açıklamıştım).
1. İlk olarak sisteme yönetici olarak giriyoruz.
sudo su
2. Kurulumunu yaptığımız Hadoop çalıştırma klasörüne gidiyoruz.
cd /usr/local/hadoop/sbin
3. Eğer daha önceden Hadoop’u başlattı isek Hadoop kapatma işlemini yapıyoruz.(Çalışan sistemi tekrar çalıştırmak istediğimizde hata verecektir).
sudo ./stop-dfs.sh sudo ./stop-yarn.sh
4. Hadoop’u başlatıyoruz.
sudo ./start-dfs.sh sudo ./start-yarn.sh
5. Eğer nokta hatası geliyorsa yani (.no such file) şeklinde bir hata geliyorsa aşağıda işlemi uyguluyoruz.
hadoop fs -mkdir -p /user/root
6. Hadoop fs -ls komutu ile, hadoop’un içinde (daha önceden çalıştırdı isek) olan klasörlerimizi görüntülüyoruz.

7. Hadoop’un içinde bulunan tüm klasörleri hadoop fs -rmr output ,temp,u.data şeklinde siliyoruz.(Daha önce output çıktısını almak için bu klasörleri yaratmadıysanız silmenize gerek yoktur).

![]()
8. Local’e kopyalanan output’u da siliyoruz.
![]()
9. HDFS’ye input datasını yerleştiriyoruz.
![]()
10. Aşağıda ki ana komutla Mahout dizinine gidip recommendItemBased işlemini gerçekleştiriyoruz.
cd /home/pinar/Downloads/trunk/bin/ ./mahout recommenditembased -s SIMILARITY_COOCCURRENCE --input u.data --output output
11. HDFS’den lokale gönderilen outputu -getmerge komutu ile birleştiriyoruz.

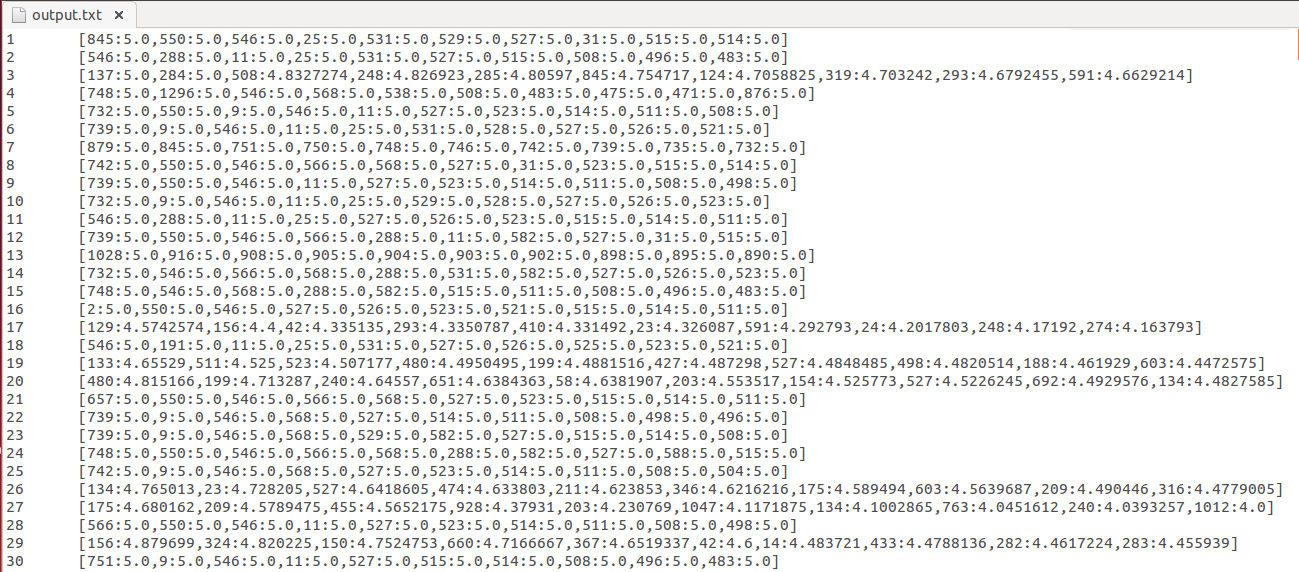
12. Ve son olarak yarattığımız output dosyasını okuyoruz.
sudo gedit output
Sonuç olarak aşağıdaki gibi bir çıktı elde ediyoruz.
Aklınızdakileri hayata geçirebilmeniz dileğiyle 🙂


